

https://github.com/verlab/accelerated_features
1. 模型
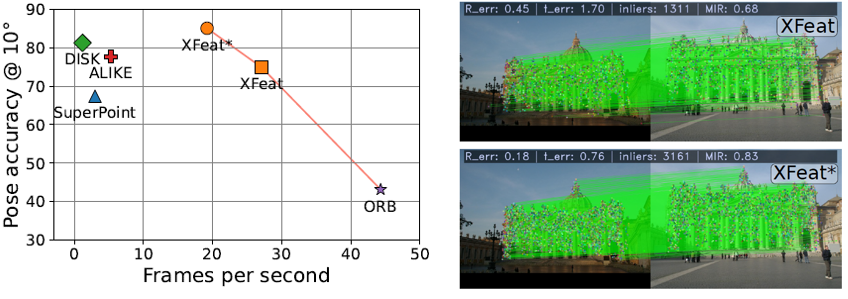
XFeat是一篇CVPR 2024的论文,提出了1个关键点检索、描述子生成、特征匹配的方法,卖点在于轻量化的同时舍弃的精度很低(它希望手机 or CPU都能实时)、又可以提取sparse关键点又可以提取semi-dense关键点。它这个是纯CNN的,所以是局部特征。如下,左图是对比了SP、DISK、ORB等方法(i5-1135G7上跑的),说明XFeat速度快的同时精度也是coparative,右图是提取sparse和semi-dense的示例,上面1311个匹配点对,下面3161个匹配点对
模型分2部分:
关键点检测和描述子生成:

如上,输入是\([H,W,1]\)的tensor,会用图像金字塔得到\(\{\frac{1}{2},\frac{1}{4},\frac{1}{8},\frac{1}{16},\frac{1}{32} \}\)的特征图。然后分2部分:
- descriptor head:取\(\{\frac{1}{8},\frac{1}{16},\frac{1}{32}\}\)的特征图,全部做上采样到\(\frac{1}{8}\)然后加起来,然后过CNN层,出\([\frac{H}{8},\frac{W}{8},64]\)形状的描述子图和可靠性图
- keypoint head: 原图切成\(8\times 8\)的patch,每个patch展平为64维向量,变成\(\frac{H}{8}\times \frac{W}{8}\times 64\)形状,然后过4层MLP,变成\(\frac{H}{8}\times \frac{W}{8}\times (64+1)\),再展回原图形状(除了多的那个1)\(H\times W\)
特征匹配:

如上,如果是sparse则直接NN,如果是semi-dense采用这个
上一步“关键点检测和描述子生成”得到的描述子是在\(\frac{1}{8}\)上的,这一步其实是refine,算具体在原图的\(8\times 8\) patch的哪个像素。方法是,先在\(\frac{1}{8}\)上做NN,得到匹配点对,每一对会有个特征\(f_a,f_b\)(这个相当于原图的匹配patch)。然后\(f_a,f_b\)拼接过1个MLP得到64维向量再resshape \(8\times 8\),当作是实际是哪个像素的热图
训练使用的数据是图片对\(I_1,I_2\)和其上的\(N\)个匹配点对\(M_{I_1\leftrightarrow I_2}\in \R^{N\times 4}\)。loss一共分4部分:\(\mathcal{L} = \alpha\mathcal{L}_{ds}+\beta\mathcal{L}_{rel}+\gamma\mathcal{L}_{fine}+\delta\mathcal{L}_{kp}\):
描述子loss:描述子类似对比学习,需要匹配点对的描述子更近而不匹配点对的描述子更远(复习CLIP和LoFTR的Dual Softmax Loss)
模型预测出的匹配点对的描述子是\(F_1\in \R^{N\times 64},F_2\in \R^{N\times 64}\),算个相似度矩阵\(S=F_1F_2^T\)。注意,\(S\)的每行做Softmax相当于\(f_i\in F_1\)去\(F_2\)中挑谁和自己最相似,\(S\)的每列相当于\(f_i\in F_2\)去\(F_1\)中挑谁和自己最相似,所以CLIP(如下伪代码)就分别在axis=0和axis=1上做Softmax,并和gt概率算交叉熵

所以本文也是这样 \[ L_{ds} = - \sum_i log(softmax(S)_{ii}) - \sum_i log(softmax(S^T)_{ii}) \]
可靠性loss:要使得描述子具有可靠性,就需要让匹配点对的描述子对越接近越好(上面对比学习loss只要求网络negetive离positive越远越好,而没有很明显地要求positive越小越好)。上面的\(S\)看作是可靠性分数,每行做Softmax取argmax作为\(\overline{R_1}\),每列做Softmax取argmax作为\(\overline{R_2}\),然后和\(R\)算L1 loss(没咋看懂,这个loss是干啥的,为啥取\(sigmoid\)) \[ L_{rel}=|\sigma(R_1)-\overline{R_1}\odot\overline{R_2}|+|\sigma(R_2)-\overline{R_1}\odot\overline{R_2}| \]
refine loss:训那个特征匹配模型的,直接热图算交叉熵loss \[ L_{fine}=-sum_i log(softmax(o_i)) \]
关键点检测loss:因为本文的关键点检测很轻量(差不多只有4层MLP),所以直接找个模型蒸馏(找的ALIKE)。因为预测的是热图,所以loss还是交叉熵 \[ L_{kp}=-sum_i log(softmax(k_{i,j})) \]
2. 实验
模型在megadepth和某个合成的COCO上训练的,1个4090花了36小时
模型分2个:XFeat是sparse,使用NN做特征匹配;XFeat*是semi-dense,使用前面的特征匹配网络做特征匹配
视觉定位aachen如下。XFeat是sparse的方法,所以还可以

做了消融实验如下,说明了:
- 同时在现实数据和合成数据上训练很好,如(i)
- 关键点的检测和描述最好分开,如(iii)
- semi-dense很需要特征匹配网络,如果没有特征匹配网络,也许还不如sparse的效果好。sparse+NN-> 42.6 vs semi-dense+NN->38.6 vs semi-dense+特征匹配网络->50.2

3. 跑
github有示例
在它的库里跑:
from modules.xfeat import XFeat
import torch
import numpy as np
from PIL import Image
xfeat = XFeat()
#Simple inference with batch sz = 1
rgb = np.array(Image.open('../mxd_glace/datasets/cambridge_undistort/GreatCourt/train/rgb/000616.png'))
rgb = torch.from_numpy(rgb).permute(2,0,1).unsqueeze(0)
print(rgb.shape)
output = xfeat.detectAndCompute(rgb, top_k = 4096)[0]
for k in output.keys():
print(k, output[k].shape)放自己的库里跑:
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), 'third_party', 'XFeat')))
from third_party.XFeat.modules.xfeat import XFeat
class XFeat_matcher:
def __init__(self) -> None:
self.xfeat = XFeat()
def extract_keypoints(self, rgb): # 提取XFeat关键点,输入[h,w,3]的rgb:ndarray
rgb = torch.from_numpy(rgb).to('cuda').permute(2,0,1).unsqueeze(0) # [1,3,h,w]
output = self.xfeat.detectAndCompute(torch.randn(1,3,480,640), top_k = 4096)[0]
return output['keypoints'].cpu().numpy(), output['descriptors'].cpu().numpy() # [4096,2]和[4096,64]
def match(self, rgb1, rgb2): # 2个rgb做特征匹配,输入[h,w,3]的rgb:ndarray
rgb1, rgb2 = torch.from_numpy(rgb1).to('cuda').permute(2,0,1).unsqueeze(0), torch.from_numpy(rgb2).to('cuda').permute(2,0,1).unsqueeze(0)
kp1, kp2 = self.xfeat.match_xfeat(rgb1, rgb2)
return kp1, kp2 # [n,2] ndarray结果:感觉也不是很强,误匹配不少
